I’ve been using the Internet in one form or another since the mid-80’s. In that time, I’ve seen a lot of strange stuff happening on our global network. On Tuesday, I experienced something extraordinary.
It all started with a text message from my partner Ged at 8:30 AM:
Mail server down. Please take a look when you can, thx.
I verified that the mail server was down from the west coast as well as the east coast, then started poking around to see what was wrong. When I looked at the server traffic, there was only one thing I could say:
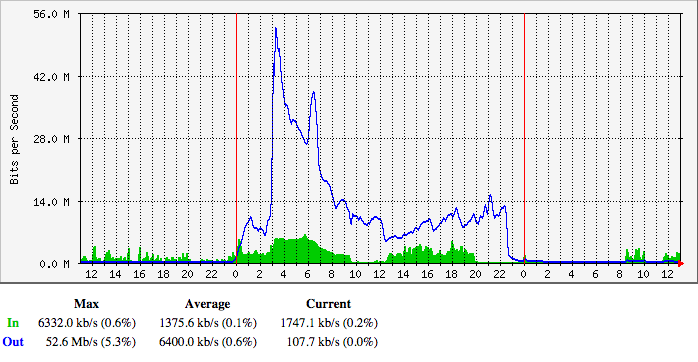
“Holy shit.”
Unless you’re a network engineer, that graph won’t mean much. The data shown is the amount of bandwidth into the Iconfactory’s main server. The blue line is the number of megabits per second for requests and the green area is the amount for responses to those requests. Normally, the blue line is much smaller than the green area: a small HTTP request returns larger HTML, CSS and images.
The number of requests peaked out at 52 Mbps. Let’s put that number in perspective: Daring Fireball is notorious for taking down sites by sending them about 500 Kbps of traffic. What we had just experienced was roughly the equivalent of 100 fireballs.
If each of those requests were 500 bytes, that’s 13,000 requests per second. That’s about a third of Google’s global search traffic. Look at how much careful planning went into handling Kim Kardashian’s butt at 8,000 requests per second.
All of this traffic directed at one IP address backed by a single server with a four core CPU.
Like I said, “Holy shit.”
Regaining Control
The first course of business was to regain control of the server. Every service on the machine was unresponsive, including SSH. The only thing to do was perform a remote restart and wait for things to come back online.
As soon as I got a shell prompt, I disabled the web server since that was the most likely source of the traffic. I was right: things quieted down as soon as traffic on port 80 and 443 was rejected. It was 9:30 AM (and you can see it in the graph above.)
The first log I looked at showed a kernel panic at 3:03 AM in zalloc. This was right at the time of the biggest spike. The system.log showed similar problems: the high level of traffic was causing all kinds of memory issues caused by too many processes.
As a test, I turned the server back on for a minute and immediately maxed out Apache’s MaxClients. Our server simply isn’t capable of handling thousands of Apache child processes (it normally runs with less than a hundred.)
So where the hell was all this traffic coming from?
Triage
Since I knew the traffic was from the web, it was likely that Apache’s logs would tell me something. Given that our Apache logs are usually in the 10 MB range, the current 100 MB log file surely contained a lot of useful information.
The first thing I noticed was a lot of requests being returned with a 403 status code. The paths for those requests also made no sense at all: one of the most common began with “/announce”. But there was also a lot of requests that looked like they were intended for CDNs, YouTube, Facebook, Twitter and other places that were not the Iconfactory.
As a test, I updated Apache’s CustomLog configuration with %{Host}i so it would show me the host headers being sent with the requests. I then turned the web server back on for 30 seconds and collected data. Indeed, the traffic we were seeing on our server was destined for someplace else.
The CHOCK was pretty proud to be serving traffic for cdn.gayhotlove.com, but I sure wasn’t.
Clearly there was some kind problem with traffic being routed to the wrong place. The most likely candidate would, of course, be DNS. While looking at IP addresses in my logs, I noticed something interesting: all of this traffic was coming from China.
The pieces were starting to fall into place. I understood the problem:
(Note: The “GFW” in responses refers to China’s Great Firewall. I’m pretty good with acronyms, but this was a new one to me!)
Now all I had to do was find a way to deal with the traffic.
Apache Configuration
My first thought was to deal with the traffic was by handling the HTTP traffic more efficiently.
We host several sites on our server and use VirtualHost to route traffic on a single IP address to multiple websites. Virtual hosts rely on the “Host:” header in the HTTP request to determine where the traffic should head, and as we’ve seen above, the host information was totally bogus.
One thing I learned is that Apache can have problems figuring out which virtual host to use in some cases:
If no ServerName is specified, then the server attempts to deduce the hostname by performing a reverse lookup on the IP address.
Remember that millions of requests had a host name that would need to be looked up. After consulting the documentation, I setup a virtual host that would quickly return a 404 error for the request and display a special message at the root directory. Here’s what it looks like:
<VirtualHost _default_:80>
ServerName default
DocumentRoot "/Web/Sites/default"
<Directory "/Web/Sites/default">
Options None
AllowOverride None
DAV Off
</Directory>
LogLevel warn
</VirtualHost>
If you run a server, take a second right now to make sure that it’s doing the right thing when presented with a bad header:
$ curl -H "Host: facebook.com" http://199.192.241.217
All of this helped deal with the traffic, but it only slowed down the amount of time it took Apache to max out the child processes. A Twitter follower in China also reminded me that their day was just beginning and traffic would be picking up. At 8 PM, the trend for traffic didn’t look good, so I turned off the web services and had a very stiff drink.
Then something strange happened at 11:30 PM: the inbound requests started to die off. Someone in China had flipped a switch.
I was tempted to bring the web server back up, but experience told me to leave things as they were. Michter’s and bash don’t make a good pair.
This problem would have to wait for another day.
Hello BitTorrent
The next morning, I tried bringing up the web server. Things ran fine for awhile, but after 10 minutes or so, Apache processes started climbing again.
Most of the traffic was to the BitTorrent /announce URL. BitTorrent clients in China still thought my server was a tracker and were noticing that port 80 was alive again.
And it’s not like there are just a couple of people using BitTorrent in China.
The direct traffic from DNS may have gone away, but secondary traffic from cached information was still killing us. At this point, the only recourse was to block IP addresses.
Blocking China
I’m a big believer in the power of an open and freely accessible Internet: I don’t take blocking traffic from innocent people lightly. But in this case, it’s the only thing that worked. If you get a DDOS like what I’ve described above, this should be the first thing you do.
The first step is to get a list of all the IP address blocks in the country. At present that’s 5,244 separate zones. You’ll then need to feed them to your firewall.
In our case, we use ipfw. So I wrote a script to create a list of rules from the cn.zone file:
#!/bin/sh
# cn.zone comes from http://www.ipdeny.com/ipblocks/
#
# build the rules with:
#
# $ build_rules > /tmp/china_rules
#
# apply rules with:
#
# $ sudo ipfw /tmp/china_rules
r=1100
while read line; do
echo "add $r deny ip from " $line " to any in";
r=$(( $r + 1 ))
done < cn.zone
You’ll want to adjust the starting rule number (1100 above) to one that’s before the allow on port 80.
After setting these new rules, traffic on our server immediately returned to normal.
Digging Deeper
Now that I had my server back, I could take some time to look at logs more closely and see if anyone else had seen similar issues.
First Hits
BitTorrent /announce traffic turned up a few clues. I had noticed a few 5 Mbps spikes in our request traffic late on Thursday, January 15th and on the following Saturday:
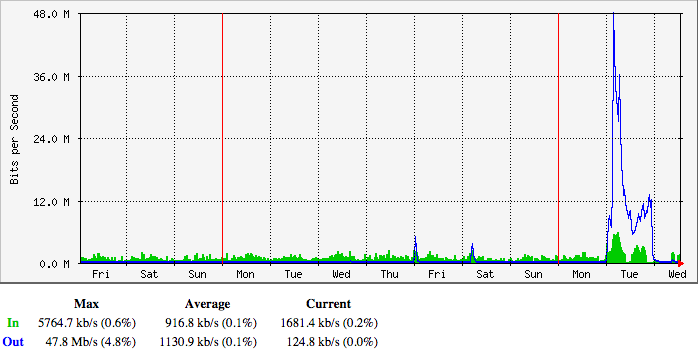
Initially, I just chalked it up to random bullshit traffic on the Internet, much like the packets from Romania looking for phpMyAdmin. In retrospect, that was dumb.
If you look at the origins of those first packets, you’ll see that it’s not a regional problem: the IP addresses are physically located all the way from densely populated Hong Kong to the remoteness of Xinjiang province (north of Tibet.)
Was this traffic a probe or an unintentional screwup? I don’t know.
(Note: I have archived all of the logs mentioned above. If you have legitimate reason to analyze these logs, please get in touch.)
We’re Not Alone
More concerning, is that other site owners are seeing similar behavior starting in early January. I took some comfort in knowing that we weren’t alone on the 20th.
But at the end of the day, every machine in China has the potential be a part of a massive DDOS attack on innocent sites. As my colleague Sean quipped, “They have weaponized their entire population.”
Conclusion
Will this happen again? For everyone’s sake, I hope not. The people of China will only end up being banned from more websites and site owners will waste many hours in total panic.
But if it does happen, I hope this document helps you deal with China’s formidable firehose.
Other Resources
If you’re using ngnix instead of Apache, here are some instructions for blocking BitTorrent requests from China.
For those of you using iptables on Linux, here’s a tutorial for blocking IPs on that platform. It’s also interesting to note that Matt’s site is running on Linode: don’t assume that big providers will offer any protection upstream.
This thread has a good discussion with other site owners experiencing the BitTorrent traffic.
Another option to consider is moving the server’s IP address. You’ll have to deal with the normal DNS propagation and reconfigure reverse DNS (especially if you’re running a mail server on the box), but this may be quick and effective way to avoid the firehose.
Updated January 24th, 2015: Added the section above with additional resources for those of you who are experiencing the problem. Good luck!
Updated January 28th, 2015: I’ve written some opinions on the incident described above.